Extracting Entries from jrnl.com
Relating to my previous post today about setting up a blog using AWS, Docker Compose, Caddy Server, and Ghost, I found the need to do some web scraping. A number of years ago, my wife began journaling her thoughts in an online service called LDSJournal.com (at least I believe that was the name). About 2 years ago, this service was acquired by a new site called jrnl.com. It seems to be a fairly neat service, but one thing we were concerned with is preserving the data should the account ever disappear.
Unfortunately, the only export option with jrnl.com seems to be the ability to download a PDF file that is created when you pay the service to have your journal entries printed physically.1 According to that same source, there allegedly will be an option to backup the journal entries without having to purchase a physical copy, but at the moment it has been over a year since that helpdesk article promised that feature to be completed before the end of 2017. Aside from that, there could be loads of potential issues extracting my wife’s writings from the PDF file they produce, depending on how it’s put together. With that in mind, I used the following steps to retrieve her content.
In a similar manner to this article: Ian London: Web Scraping - Discovering Hidden APIs, I used the outgoing connections from the jrnl.com web application to identify their hidden API with which to access the entries. After logging into the service and navigating to the journal entries, you can view the request headers that your browser sends to jrnl.com to retrieve the entries and other content. The API key is one of these headers, with the first portion visible in the image below under Authorization.
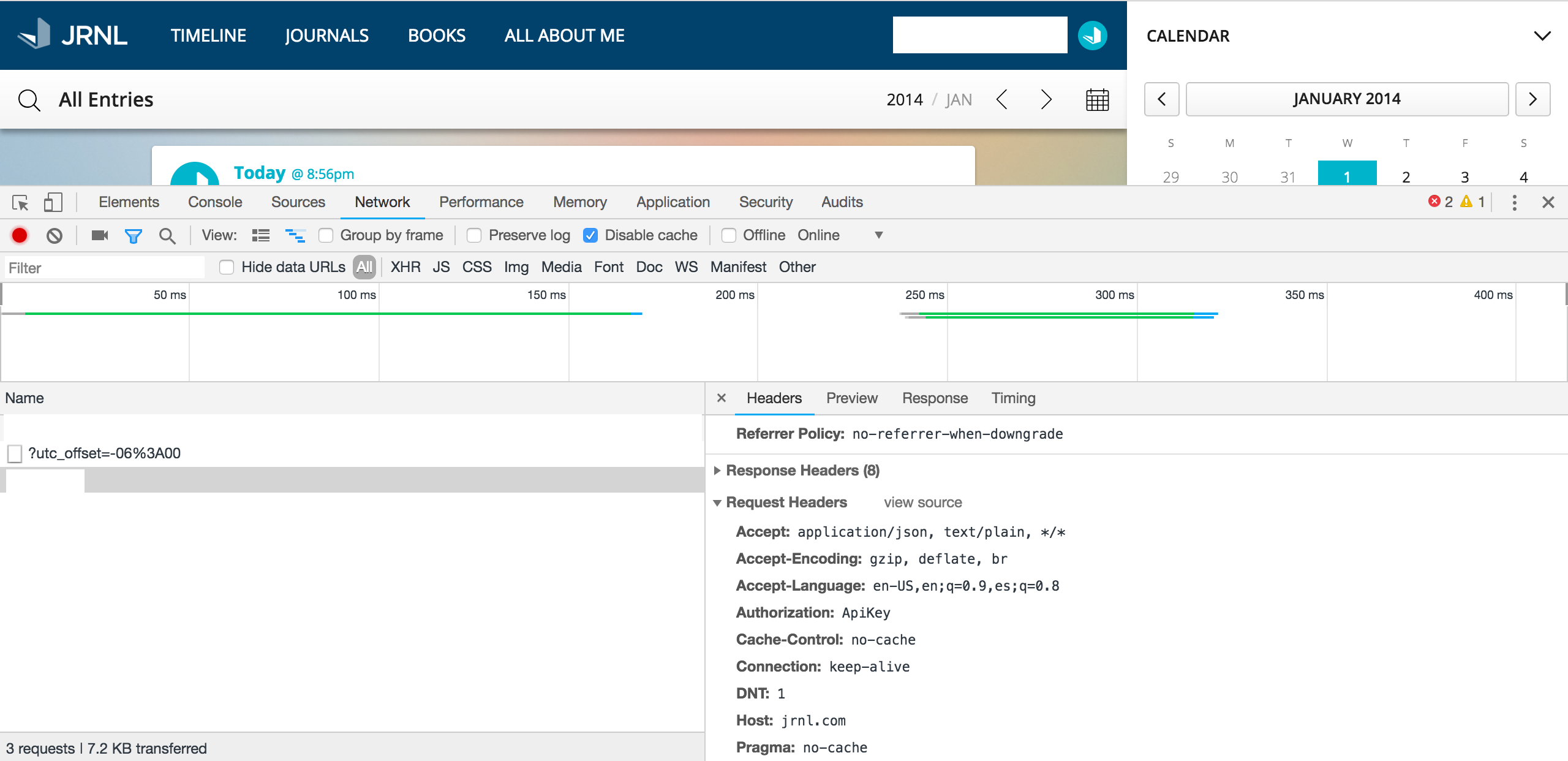
Getting the API Key
Some more poking around showed that the base url for the API is https://jrnl.com/api/v1/, and the API endpoint for the entries is, unsurprisingly, https://jrnl.com/api/v1/entry. Using a REST API tool called Insomnia, we can plug in the API key and use the endpoint with the limit option set to allow more entries returned: https://jrnl.com/api/v1/entry?limit=250.
Then using something like the following Python script, you can convert the posts into a format for import elsewhere. This script is one I used to prepare the entries for import into the Ghost CMS platform which I set up following the instructions in my previous post. There is a little more post-processing to get it into Ghost, if you made it this far then following the Ghost documentation will get you the rest of the way. The script assumes that the entries from jrnl.com are isolated and saved as a JSON array in a file called posts.json.
#! /usr/bin/env python3
from datetime import datetime
import json, os
def millis(x):
return int(datetime.fromisoformat(x).timestamp() * 1000)
with open('posts.json') as f:
posts = json.load(f)
new_posts = []
for post in posts:
temp = {
'id': post['id'],
'title': post['title'],
'slug': post['title'],
'html': post['content'],
'image': None,
'featured': 0,
'page': 0,
'status': 'published',
'language': 'en_US',
'meta_title': None,
'meta_description': None,
'author_id': 1,
'created_at': millis(post['created']),
'created_by': 1,
'updated_at': millis(post['modified']),
'updated_by': 1,
'published_at': millis(post['entry_date']),
'published_by': 1
}
new_posts.append(temp)
with open('new_posts.json', 'w') as f:
json.dump(new_posts, f, indent=2)
Comments